
Anonymous Enough to Share, Personal Enough to Police?
The unresolved contradiction in the Commission’s Article 6(11) DMA search-data remedy

In my previous post, I explained why Article 6(11) of the Digital Markets Act matters: it requires Google, as a gatekeeper search engine, to grant rival search providers access to ranking, query, click, and view data on fair, reasonable, and non-discriminatory terms. The policy aim is contestability. The unresolved problem is privacy. The Commission’s proposed implementation seeks to square that circle by requiring Google to share useful search data only after anonymisation. But the deeper one looks, the more unstable the category becomes: the data are said to be anonymous enough to fall outside the GDPR, yet still risky enough to require contracts, purpose restrictions, audits, deletion duties, and enforcement machinery. This post picks up where the first one left off and asks whether Article 6(11) is really about anonymised data at all, or about a new and uneasy category of regulated access to de-identified behavioural data.
Google plainly has an incentive to resist forced data sharing. Nobody should romanticise that. But it would be just as mistaken to dismiss every privacy objection as mere strategic delay. On Article 6(11) of the Digital Markets Act, Google’s concern points to a real structural problem in the Commission’s current approach. The Commission appears to want a dataset that is sufficiently anonymous to fall outside the GDPR, yet still dangerous enough to justify contractual controls, recipient policing, purpose restrictions, audits, deletion duties, and breach procedures.
That is not a side issue. It is the whole issue.
The Commission’s Google Search data-sharing process is presented as a contestability remedy. Google, as a gatekeeper, must grant other online search engines access to ranking, query, click, and view data on FRAND terms. The proposed measures address eligibility, data scope, anonymisation, pricing and the acquisition process. The Commission has also indicated that eligible recipients may include AI chatbots with search functionality.
Nobody disputes that search data is competitively valuable. The harder question is whether Europe can require the sharing of intensely revealing behavioural data while speaking as if the privacy problem has already been solved by calling the output “anonymised”.
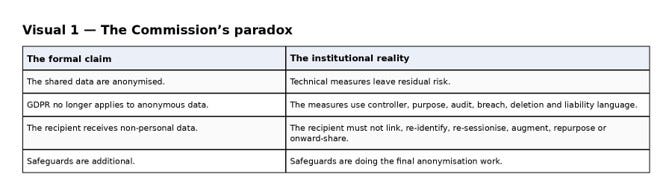
At the heart of the proposal lies a contradiction. If the shared data is genuinely anonymous, then the GDPR no longer applies. In principle, that should mean no need for the thick layer of GDPR-like machinery that follows. Yet the Commission’s own preliminary measures do not indicate that the privacy question has been resolved.
They say that technical measures reduce re-identification risk only to a residual level. Contractual measures are then needed to bring that residual risk down to an insignificant level. That formulation matters. It means the final move from “risky but transformed” to “safe enough to share” is not purely technical. It is institutional. It depends on who receives the data, what they are forbidden to do, what auxiliary datasets they already hold, how those datasets are kept separate, how they are audited, and what happens if they breach.
This is precisely why the usual shorthand — “the data are anonymised, so the GDPR falls away” — is too crude for what the Commission is actually building.
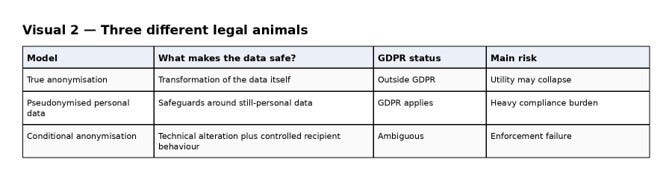
The Commission seems to be collapsing three distinct categories into one.
First, there is true anonymisation, where the transformation of the data itself means the individual is no longer realistically identifiable. In that case, the GDPR is out of the picture.
Second, there is pseudonymised personal data, where the data remain personal but are subject to technical and organisational safeguards. Here, the GDPR clearly continues to apply.
Third, there is something more unstable: conditional anonymisation. That is the zone in which data are said to be anonymous only because technical alteration is combined with tightly controlled recipient behaviour. The data are not merely transformed. They are governed.
The Commission appears to be constructing this third model while using the rhetoric of the first.
That may be intellectually defensible in a narrow DMA setting. The joint Commission/EDPB draft guidelines on the DMA/GDPR interplay accept that technical measures are indispensable, but that organisational, administrative and contractual measures may complement them in the Article 6(11) environment. But that is a much more delicate claim than “the data are anonymous”. At most, it means that identifiability may be rendered sufficiently unlikely for a particular recipient, in a particular institutional environment, under a particular set of constraints.
That is much closer to governed non-identifiability than to robust anonymisation.
The architecture gives the game away.
The proposed measures tell recipients what they must not do. They must not link the Search Dataset with auxiliary datasets. They must not re-identify. They must not further sessionise. They must not reverse or weaken anonymisation. They must keep the data separate from advertising and analytics datasets. They must use the data only for the specified online search purposes. They must respect retention limits, avoid onward sharing, and document downstream datasets and models influenced by the shared data.
That is not how one normally speaks about a dataset whose anonymity is complete and settled. It is how one speaks about a controlled-access arrangement in which the residual privacy risk has not disappeared but is being managed through governance.
And the weakness of that move becomes clearer the moment one asks a very ordinary GDPR question. What is Google supposed to be when they receive a deletion request for a user’s search data?
The deletion problem, sharpened
The deletion problem exposes the instability of the Commission’s position. Start with Google itself. Search data are not processed under one simple legal basis. In ordinary Search, some processing is necessary to deliver the service: the query must be processed to return results. Other processing is closer to service improvement, security, fraud prevention, measurement, personalisation, advertising, or compliance with legal process. Some of that may rest on contract, some on legitimate interests, some on consent, and some on specific legal obligations. Google’s own public materials reflect this mixed picture: users can delete activity saved in their account, but Google may retain certain information for limited purposes such as security, fraud and abuse prevention, financial record-keeping, legal or regulatory requirements, or in anonymised form.
That matters because the right to erasure operates differently depending on the basis and purpose of processing. If data are processed on legitimate interests, erasure and objection remain live questions: the controller may have to stop unless it can show overriding grounds. If data are processed under a specific legal obligation, erasure can be refused or limited to the extent that continued processing is necessary to comply with that obligation. If data have been genuinely anonymised, the GDPR falls away, and there is no user-level erasure right because there is no longer personal data relating to that user.
Article 6(11) complicates this because it may create a new layer of legal obligation. Once the Commission’s specification measures become binding, Google may say: for the purpose of producing the Article 6(11) Search Dataset, it is under a legal obligation to process relevant search data, apply the required technical measures, and share the resulting anonymised dataset. If that is the theory, it should be stated openly. Article 6(11) would not merely be a competition access duty. It would also operate as a legal basis for processing personal search data before anonymisation, potentially limiting the practical effect of user deletion requests during that pre-sharing phase.
But that is a serious rights consequence, not a technical footnote. Suppose a user deletes their search activity before the Article 6(11) dataset is produced. Does Google still include those records because the DMA requires parity with the data Google uses to optimise Search? Or does the deletion remove those records from the pool that can be transformed and shared? If the answer is “include them anyway”, then Article 6(11) is functioning as a legal obligation to continue processing notwithstanding erasure. If the answer is “exclude them”, then the shared dataset is not simply all useful search data; it is all useful search data minus whatever has been removed before anonymisation. The Commission’s current framing does not confront that choice.
The problem becomes even sharper after sharing. If the Search Dataset received by a third-party OSE is genuinely anonymised, neither Google nor the recipient should be able to locate a particular user’s records in response to an erasure request. That is the point of anonymisation. A downstream deletion request should not be answerable at the record level.
But if the recipient can answer the deletion request, if it can say, “yes, we have found and removed your search records”, that is a very awkward fact for the anonymisation claim. It means the recipient, or someone upstream, has a way to single out, map, suppress or otherwise act upon records relating to that user. That may be compatible with pseudonymisation, keyed deletion, or controlled de-identification. It is much harder to reconcile with a claim that the data have left the GDPR altogether.
Nor is the Commission’s own draft really about user-level deletion. The proposed measures address retention limits and the secure erasure of the Search Dataset after the maximum retention period or upon termination. That is dataset-level lifecycle control. It is not the same as a user’s Article 17 erasure request, which follows the data through the Article 6(11) chain.
So the deletion problem has two horns. If deletion remains possible downstream, the anonymisation claim is fragile. If downstream deletion is impossible, the user’s erasure right effectively ends at the point of anonymisation. That may be lawful if anonymisation is genuine and if the pre-anonymisation processing was lawfully grounded. But it becomes much harder to defend when the Commission simultaneously insists on controller roles, purpose limitation, anti-linkage duties, retention limits, breach processes, audit and secure erasure to manage residual risk.
That is the deeper contradiction. The Commission cannot treat the dataset as sufficiently anonymous to preclude user-level deletion, but as risky enough to require GDPR-like machinery for every recipient. If Article 6(11) is intended to create a legal obligation to limit erasure before sharing, the Commission should say so. If the data are meant to be anonymous after sharing, the Commission should also accept the consequence: no recipient should be able to honour a user-level deletion request without undermining the very claim of anonymisation.
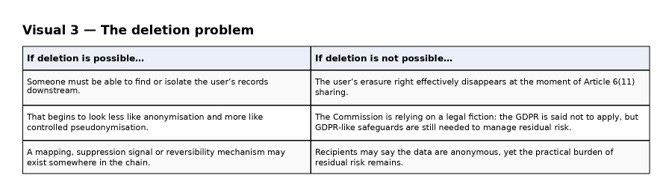
The deletion problem exposes the fuzziness of the Commission’s position. In ordinary GDPR logic, the position is at least conceptually clear. Either the data are personal data, in which case an erasure request can bite; or the data have been genuinely anonymised, in which case the GDPR no longer applies, and the controller or recipient should not be able to locate a particular user’s records.
Under the Commission’s Article 6(11) model, that distinction becomes difficult to maintain. That is the problem in its sharpest form. Either deletion is possible, in which case the anonymisation claim looks fragile. Or deletion is impossible, in which case the Commission is relying on a legal fiction that extinguishes practical rights while preserving a structure of residual-risk governance.
One need not be sympathetic to Google’s commercial interests to see that this is not a trivial conceptual gap.
The Court of Justice’s reasoning in EDPS v SRB does not rescue the Commission from this difficulty. The Court accepted that the same dataset may not be personal data for every actor in every context. But that relative approach to identifiability does not collapse the difference between truly anonymous data and data that remain safe only because recipients are constrained, monitored and forbidden from doing certain things.
The institutional design is also awkward.
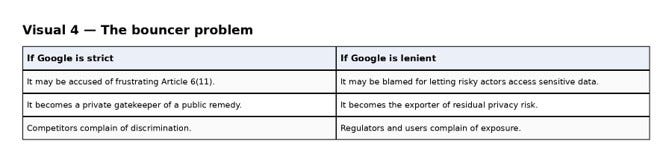
The Commission’s measures place Alphabet in a front-line enforcement role. Google must impose the contractual framework, receive assurance reports, react to breaches, and, in some cases, suspend or terminate access. Yet Google is also the very gatekeeper whose incentives the Commission is seeking to discipline.
That creates a familiar but unresolved problem. If Google is strict, it will be accused of frustrating Article 6(11). If it is permissive, it may be blamed for allowing risky actors to access highly sensitive behavioural data. The Commission cannot simultaneously distrust Google’s market power and rely on it to serve as the bouncer for a privacy-sensitive public remedy.
That is not a stable institutional compromise. It is a pressure point waiting to become a blame game.
Search data is not ordinary data.
This matters because search data are unusually intimate. Queries are not just signals of shopping intent. They may reveal illness, sexual orientation, religious doubt, debt, addiction, family breakdown, political fear, immigration anxiety, employment insecurity or moments of acute vulnerability. The Commission’s measures attempt to manage this through suppression, generalisation, location thresholds, timing adjustments and mini-sessions.
But the tail of search is where both the privacy risk and the competitive value often sit. Rare queries are dangerous because they are distinctive. They are valuable for much the same reason.
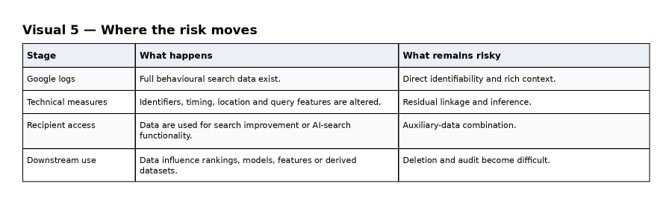
The risk, therefore, does not disappear. It moves.
It begins with Google holding the full behavioural record. It shifts when technical measures alter identifiers, timing, location and query features. It shifts again when recipients combine the data with their own systems to improve search or to add AI search functionality. And it shifts yet again once the shared data influences downstream rankings, models, features or derived datasets.
That final stage matters more than the Commission’s present framing fully recognises. A deletion obligation does not necessarily undo the use of data in a trained system. A prohibition on re-identification does not prevent a bad actor from attempting to do so. A termination right does not recall copied, leaked or derived data. Contracts are highly effective against honest actors, moderately useful against careless actors, and far weaker against bad actors once the data have moved.
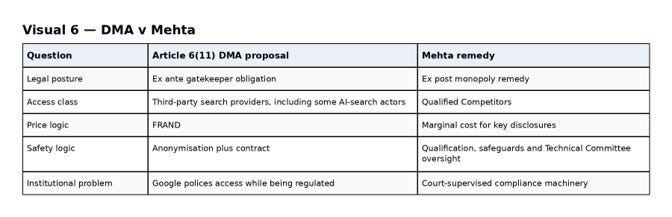
This is where Judge Mehta’s remedy in the US Google search case offers a useful comparison, not because the US solution should be transplanted wholesale, but because it is more explicit about the parameters of access. In the US Final Judgment, Google must provide certain Web Search Index data and user-side data to “Qualified Competitors”, subject to privacy and security safeguards. The remedy does not require the disclosure of algorithms, ranking signals or post-trained LLMs. The court’s broader remedial reasoning can also be traced through the earlier opinion.
The key point is not the details of American antitrust doctrine. It is the clarity of institutional design. The US remedy revolves around qualification, supervision and bounded disclosure. Access is not simply opened up and then patched with contractual language. It is mediated through a defined class of recipients, ongoing oversight and a more explicit compliance architecture.
That throws into relief the weakness of the Commission’s current approach. If Europe is serious about Article 6(11), it needs a stronger qualified-recipient regime: independent certification, continuous re-certification, meaningful sanctions, change-of-control review, direct escalation to the Commission and DPAs, strong separation from advertising and analytics infrastructures, restrictions on onward transfer, traceability of derived datasets and models, and genuinely verified deletion where possible.
The real issue: what kind of legal object is this?
The Commission should also be more candid about the legal category it is creating. If residual risk becomes insignificant only because recipients are contractually and institutionally constrained, then the data are not anonymous in the ordinary sense. They are de-identified behavioural data made governable within a regulated access environment.
That may still be enough for a contestability remedy. But it is not the same as ordinary anonymisation, and it should not be described as such.
This is where Google’s objection deserves more serious engagement than it often gets. Of course, Google benefits from delay, narrow access and maximal caution. But Google is also right to ask who bears the privacy risk when “anonymous” data remains dependent on contract, supervision and controlled behaviour. If the Commission wants Google to dismantle a search-data bottleneck, it should not casually make Google the unwilling insurer of a governance model the Commission has not yet fully built.
The hardest question is therefore not whether search data should ever be shared. It is whether the Commission can coherently maintain that the data are anonymous while simultaneously surrounding them with a dense web of GDPR-adjacent obligations, knowing the residual risk has not disappeared.
That is the unresolved contradiction at the heart of Article 6(11).
And it leads to my final provocation: If contracts are what make the residual risk insignificant, are we still dealing with anonymisation? Or with regulated access to de-identified personal data?